
智东西7月26日报道,今天一早,大模型独角兽智谱AI正式发布视频生成工具清影,可支持文生、图生6秒时长的视频,即日起在PC端、手机App端以及小程序端面向所有C端用户免费开放。
先来看看效果,以下是几个官方放出的文生和图生视频案例,覆盖人像、动物、3D卡通等场景:


从Demo来看,清影的生成效果虽然相比Sora等还有一定进步空间,但就整体而言流畅度、运动幅度等都很不错,无论是人物表情、动作,还是光影变化、镜头移动,都没有明显的卡顿和突兀感,对运动幅度的把控也恰到好处,不会看起来像PPT也不会过于夸张。
此外,虽然生成是完全免费的,但生成视频需要排队,智谱AI提供了两种加速排队的订阅方式,包括5元加速1天、199元加速1年。
清影API今天也同步上线,企业和开发者都可以通过调用API的方式,体验并使用清影的文生、图生视频能力,据称这也是国内上线的首个视频生成API。
据智谱AI CEO张鹏解读,清影基于自研的底座视频生成模型CogVideoX打造,能将文本、时间、空间三个维度融合起来。该模型参考Sora算法设计,采用了DiT架构,相比前代CogVideo模型推理速度提升了6倍。
智谱AI成立于2019年6月,起源于清华大学计算机系知识工程实验室,专注于开发新一代认知智能大模型。一直以来,智谱AI以对标OpenAI全模型产品线为线索,陆续研发了包括文本、代码、图像、Agent等方面的自研模型和产品矩阵。此次发布基于CogVideoX的清影,使其大模型矩阵又扩充类一个模态。
值得一提的是,这也是国内做语言大模型起家的大模型独角兽,首次推出视频生成产品——之前这个赛道更多的是字节、快手等短视频大厂,以及爱诗科技、生数科技等专注于视频生成模型的创企。
清影具体有哪些特点?其底层模型在哪些方面做了创新?具体效果如何?智东西第一时间上手实测了一番,有以下几点发现:
1、简短的提示词效果更好,复杂指令下会丢失细节。
2、人手仍是重灾区,容易出现画面闪烁的现象。
3、生成很快,但加上排队等待时间仍达到1-2分钟。
4、相比图生视频,文生视频的稳定性更高。

当然,有限次的体验无法做到全面,也欢迎感兴趣的读者朋友,在评论区分享体验感受和新发现~
一、半分钟生成6秒视频,复杂指令、内容连贯
清影主要有4个特点:生成速度快、复杂指令遵从能力强、内容连贯性高以及画面调度幅度大。
首先在生成速度上,清影AI据称可以在30秒内生成一段6秒、帧率16fps、分辨率1440*960的视频。

▲实时演示视频生成(动图有加速)
其次,在复杂指令遵从能力上,智谱AI自研了视频理解模型,用于为视频数据生成高度吻合的文本描述,进而构建了海量高质量视频文本对,提升了指令遵循度。

▲复杂指令演示
清影的第三个特点是内容连贯性,能够比较好地还原物理世界当中的一些运动的过程。
例如基于这张大家熟悉的杜甫画作,清影让杜甫不仅动了起来,而且非常自然顺滑地端起了一杯咖啡。

▲内容连贯性
最后在画面调度方面,清影采用文本、时间、空间融合的Diffusion Transformer架构,可生成遵循特定运动规则的动态视频。
智谱AI豪迈地放出了几十个Demo,其中不乏有一些效果惊艳,比如这个:木头上长出两朵奇特的透明塑料花。

“透明塑料花”不是真实存在的,清影的想象力和审美在这个案例中得以展现。
再比如这个:比得兔开小汽车,游走在马路上,脸上的表情充满开心喜悦,全景画面。

清影绘制的兔子表情很丰富,没有出现五官扭曲的情况,前后景别还加了景深处理。
人像案例清影也拿捏住了,比如这个提示词:油画风格,美丽的少女侧颜,光透过树形成斑驳的影子,柔光落在她脸上。

整个画面光影对比鲜明,不过漏失了“油画”、“斑驳的影子”等细节。
二、实测上手有惊艳也有翻车,付费加速有些鸡肋
官方演示虽好,但清影到底好不好用,还是得自己试一下才能知道。打开清影网页端,可以看到有文生、图生视频两种功能。

▲清影网页端
在文生视频中,我可以选择视频风格,包括卡通3D、黑白老照片、油画等;也可以选择情感氛围,包括温馨和谐、生动活泼、紧张刺激、凄凉寂寞等;运镜方式包括水平、垂直、推近、拉远四种。
在图生视频中,我可以为图片添加文字描述,如果不知道写什么也可以空着,或是让系统随机生成一个提示词。

▲两种模式
首先我尝试了一组动物场景的提示词,第一个为:一只蓝猫在猫爬架上,正在吃主人递过来的芝士汉堡,情感氛围选择了温馨和谐。

可以看到,清影准确理解了提示词,整体效果还是很不错的。对于提示词中细节,包括猫的品种、汉堡的种类以及“递过来”的动作等,都表达得比较精准,人手也没有翻车。
第二个提示词为:一只橘猫把鼠标推下桌子,情感氛围为生动活泼。

这次清影表现得一般,鼠标上莫名其妙拴了一只小老鼠就算了,“推下桌子”的动作也是完全没有体现。
前两个提示词都属于写实场景,第三个提示词则有些“魔幻现实”:一只白猫在车里驾驶,穿过繁忙的市区街道,背景是高楼和行人,情感氛围为紧张刺激。
清影对于这个提示词的理解和呈现都还比较准确,背景中动态场景的运动幅度、一致性也比较高,但是稳定性还有所欠缺,画面会出现抖动的情况。
第二组提示词我尝试了人物场景。首先来试试经典的吃面:一个男人坐在桌边吃面条,情感氛围为凄凉寂寞。

在这个经典难题上,清影的表现还算可以,乍一看没什么错误。但细看之下,男人吃面的餐具用的是勺子,面条的形态也有些僵硬。
第二个提示词是:一个女孩坐在米色沙发上,专心地用钩针勾着一顶浅蓝色帽子,情感氛围为温馨和谐。

这条提示词中我加入了色彩的细节,清影都准确地表现了出来。女孩的钩织动作也比较真实,就是人手非常“鬼畜”。
第三个提示词为:漂亮的水色瞳孔特写,写实风格,超清,情感氛围为凄凉寂寞。

清影生成的视频基本上满足了我的预期,不过在特写镜头下,人物的皮肤和毛发都显得有些“油腻”。
最后我尝试了让清影自己生成提示词,它直接整了这么长一段:雨天的咖啡馆,以窗户为媒介拍摄一个英式咖啡馆内部,要清晰的拍摄咖啡馆内部,捕捉咖啡馆内的温馨氛围,然后变焦,对焦在雨滴拍打的窗户上。细节上,注意捕捉顾客们的交谈和笑容,以及雨水在窗户上形成的光影效果,营造出舒适而宁静的氛围。

结果很遗憾,清影自己给自己挖了个坑,生成的不能说是视频,称之为动图都有些为难。画面仅仅是平移放大了一圈,也没能体现提示词中的大部分内容。
体验完文生视频后,我又尝试了图生视频。
首先在上传图片时,清影会提醒我对图片进行裁切,且只能裁成进行固定比例的横图,这就造成了一定的局限性。上传图片之后,我输入提示词:花瓣在风中摇动。

生成效果还是比较准确的,不过这个提示词本身的难度也不算大。
接着我上传了一张静物图,这次没有输入提示词,看看清影会如何自由发挥。

这张图上有很多独立的物体,清影并没有让它们整体运动而是为每个“小团子”添加了不同动态,整体画面比较生动活泼。
第三张图我上传了一张戴着墨镜的人像,提示词为:男孩把墨镜摘下来。

这个提示词的难度很大,而且涉及到“无中生有”的部分。清影成功表现了“摘墨镜”这一动作,不过摘了是摘了,但没完全摘,墨镜还在人脸上挂着,视频后半段还出现了人体不自然的扭曲。
如果不要求它凭空生成人脸又会如何?我有上传了一张举着摄像机的人像照片,提示词改为:男孩转身面向镜头。

结果这次清影反而整了个人脸出来,就是没有眼白有些吓人……不过忽略脸的话,这次生成的效果转身幅度更大,人物的头发也随风飘动,就是他手中的器材变了个模样,人手也有些不自然。
一番体验下来,清影生成视频的效果有的惊艳到我,比如第一个小猫吃汉堡的例子,文字理解十分准确;也有的翻车严重,比如咖啡厅、橘猫的例子中,失误都比较大。
整体来看,清影在生成速度上确实比较快,虽然较宣传的30秒还有些偏差,但差不多1分钟左右就能生成视频;在运动幅度、语义理解等方面,会比较看运气,不过这也是所有视频生成工具的通病。与市面上其他公开可用的工具相比,清影在生成时长、清晰度方面还有一定的进步空间,不支持画面比例的选择也是一大遗憾。
值得一提的是,清影目前的视频生成是完全免费的,不需要会员订阅也没有数量限制。不过在排队生成的过程中,清影提醒我可以加速。点击加速的按钮,可以看到它提供了两种订阅方式:5块钱加速1天,或是199元加速1年。

▲加速排队
该说不说,这个价格还是很实惠的,但为啥我加完速排队时间一点也没减少呢……唯一的变化就是,从“排队中”变成了“加速排队中”。可能费用太便宜了,大家都加速就相当于没加速吧(doge)。
三、自研端到端视频模型,首个API同步上线
清影基于智谱AI自研的底层模型CogVideoX打造,具有内容连贯、可控性高等特点。
在内容连贯性方面,智谱AI自研了一个高效的三维变分自编码器结构,称之为3D VAE。它能够将原视频空间压缩至2%的大小,大大减少视频扩散生成模型的训练成本和难度,再配合3D RoPE(旋转位置编码)模块,有利于在时间维度上捕捉帧间关系,建立食品中的长程依赖。
在可控性方面,智谱AI自研了一个端到端的视频理解模型,用于为海量的视频数据生成详细的、贴合内容的描述文本,从而增强模型的文本理解和指令遵循的能力,使生成视频更符合用户的输入,理解超长的复杂指令。
在模型结构上,CogVideoX采用了将文本、时间、空间三个维度全部融合起来的Transformer架构,摒弃了传统的交叉注意力(Cross-Attention)模块,将文本和视频两个不同模态的空间进行对齐,能够更好地进行模态交互。

▲CogVideoX特点
张鹏称,在CogVideoX的研发过程中,智谱AI有一次验证了Scaling Law在视频生成方面的有效性和可靠性,未来团队会在继续扩大数据规模和模型规模的同时,寻找更具突破式创新的模型架构。
智谱AI又一次实现了对OpenAI全模型产品线的对标。
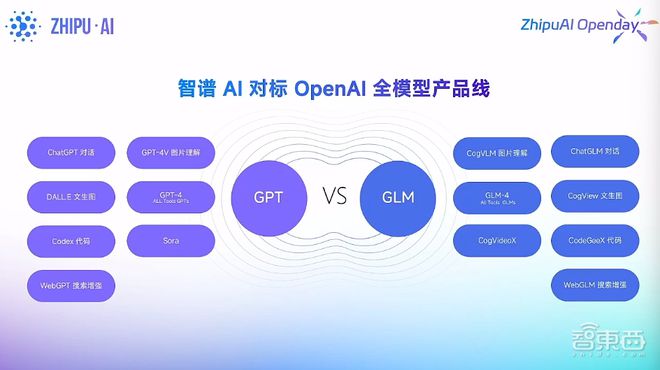
▲智谱AI对标OpenAI全模型产品线
在算力方面,清影是在北京亦庄AI公共算力平台上训练而来的。数据层面,智谱AI与Bilibili、华策影视等进行了合作。
张鹏谈道,虽然视频生成模型才刚刚起步,但已经受到了很多产业和客户侧的需求,涉及电商产品宣传、影视特效等领域。
今天起,清影AI也同步在智谱AI大模型开放平台上线了API,企业和开发者都可以通过调用API的方式体验并使用CogVideoX的文生、图生视频能力,据称这也是国内上线的首个视频生成API。
随着清影能力的加入,智谱AI旗下的AI助手清言App在功能的全面上再下一城,覆盖对话、生图、代码、Agent和视频。
智谱AI还准备了一个One more thing——视频生视频能力。不过准确来说,这相当于是一个手动视频生视频的能力:基于智谱AI近日开源的视频理解模型CogVLM2-Video,用户可以上传视频并提取出详细的文字描述,再将文字输入清影,实现“视频生视频”的效果。
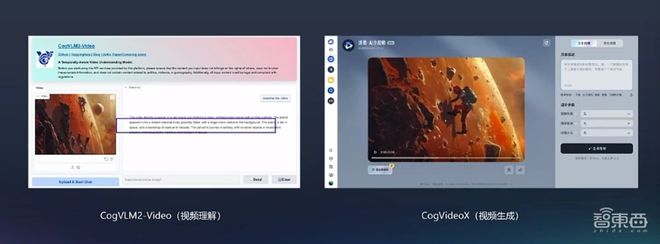
▲视频生视频
结语:又一强力玩家入局AI视频生成
Sora发布后,AI视频生成迎来“第二春”,无论是技术、产品的迭代,还是资本市场的关注,都达到了新的高度。光是本周,就有快手宣布全球上线、爱诗科技发布第二代模型,以及今天智谱AI入局等重磅进展。(视频生成大战2.0!大厂狂卷底层模型,创企5个月吸金44亿)
不同于此前的文本、图像模型赛道,国内长期处于追逐OpenAI等海外企业进展的状态。在视频生成领域,国内的大厂、创企在短短几个月内实现弯道超车,不仅打磨出了高质量的底层模型,而且个个公开可用甚至免费,给至今仍是期货的Sora上了一课。
内容链接:https://www.hpaper.cn/19835.html